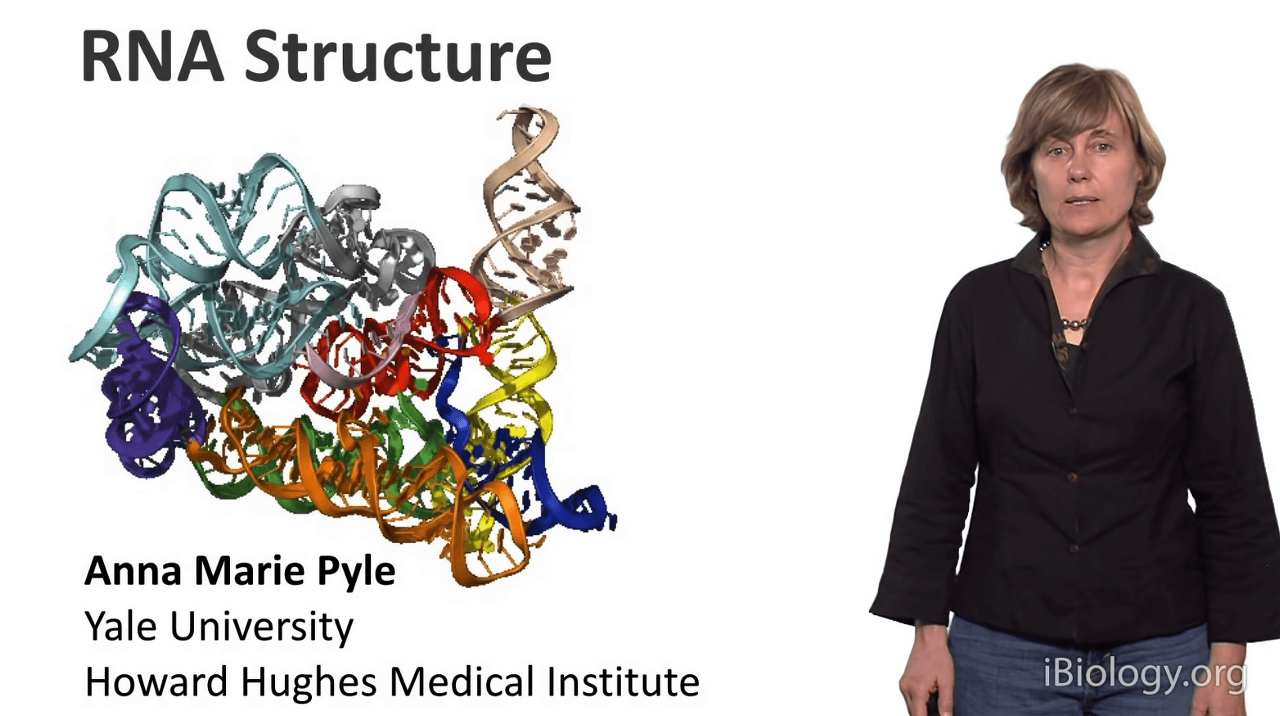
I'm Anna Marie Pyle from Yale University,
and today I'd like to tell you about RNA structure.
And I'm hoping, by the end of this seminar,
that you'll be thinking about RNA as a much more complex molecule
than you might have thought about it before.

One of the things that's important to keep in mind is that,
for any biomolecule, very often one sequence will lead to a unique structure,
and this is true for proteins and it's also true for many RNA molecules.
Today, I hope to tell you how that can be achieved.
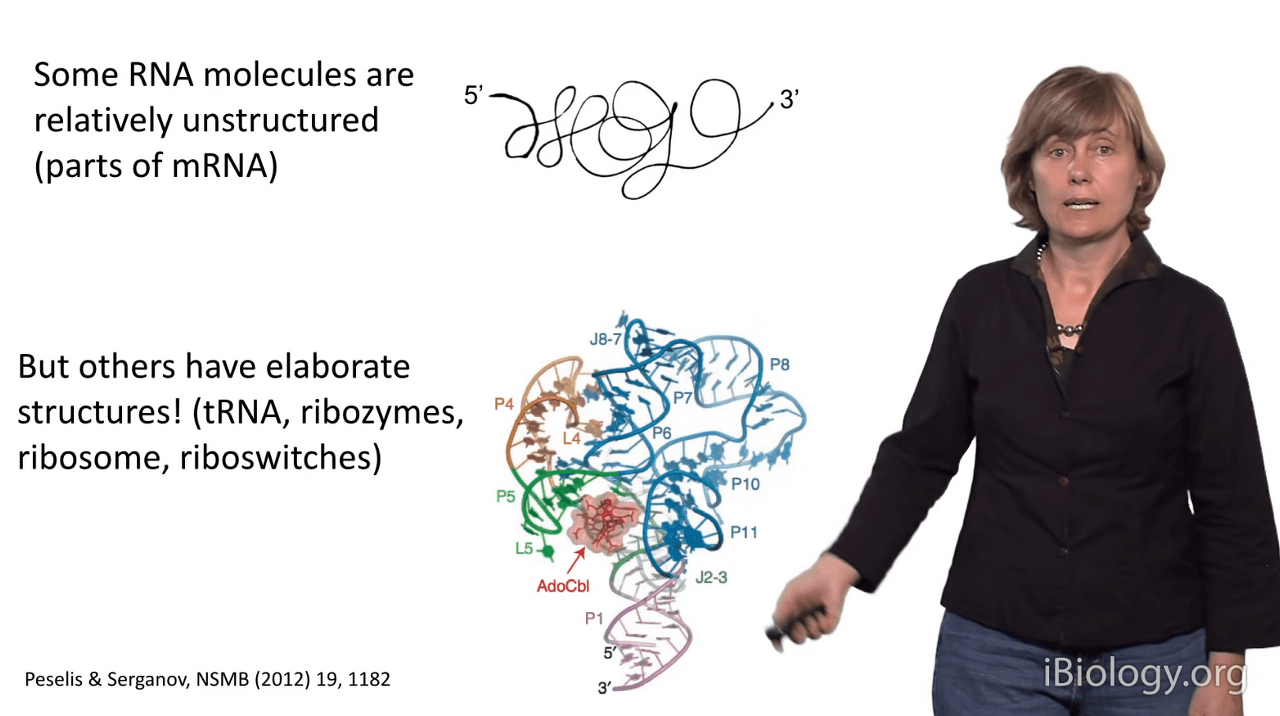
Now, some RNA molecules are actually unstructured,
like messenger RNAs (mRNAs) that contain the code for translating your protein.
But other RNA molecules have elaborate structures,
such as tRNA molecules, ribozymes - which are catalytic RNAs,
the ribosome - which is the factory that makes your proteins,
and riboswitches.
I'm showing you a riboswitch in this image here.

RNA molecules are often highly complex in structure
and it's important to remember that
structured RNAs are involved in almost every aspect of gene expression.
I'm showing you some examples here.
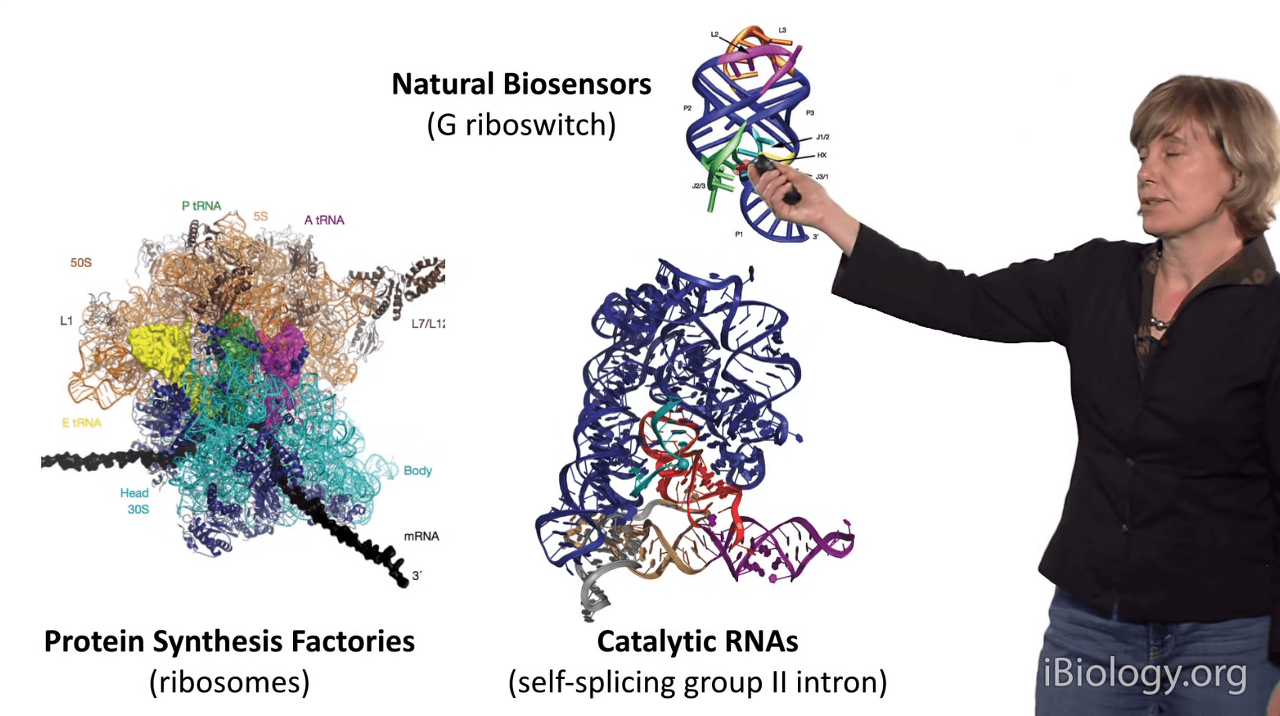
In this case, this is one of nature's biosensors:
it's called a riboswitch, and it's important for bacteria
so that they can sense metabolites in their environments
and signal back to the cell.
This is a catalytic RNA called a self-splicing group II intron,
and it's a molecule that can cut and stitch RNA and DNA molecules
so that they can go on to be functional.
And here, this giant RNA is your protein synthesis factory,
which ironically is an RNA molecule and it is probably one of the largest
and most highly structured RNAs in our cells.
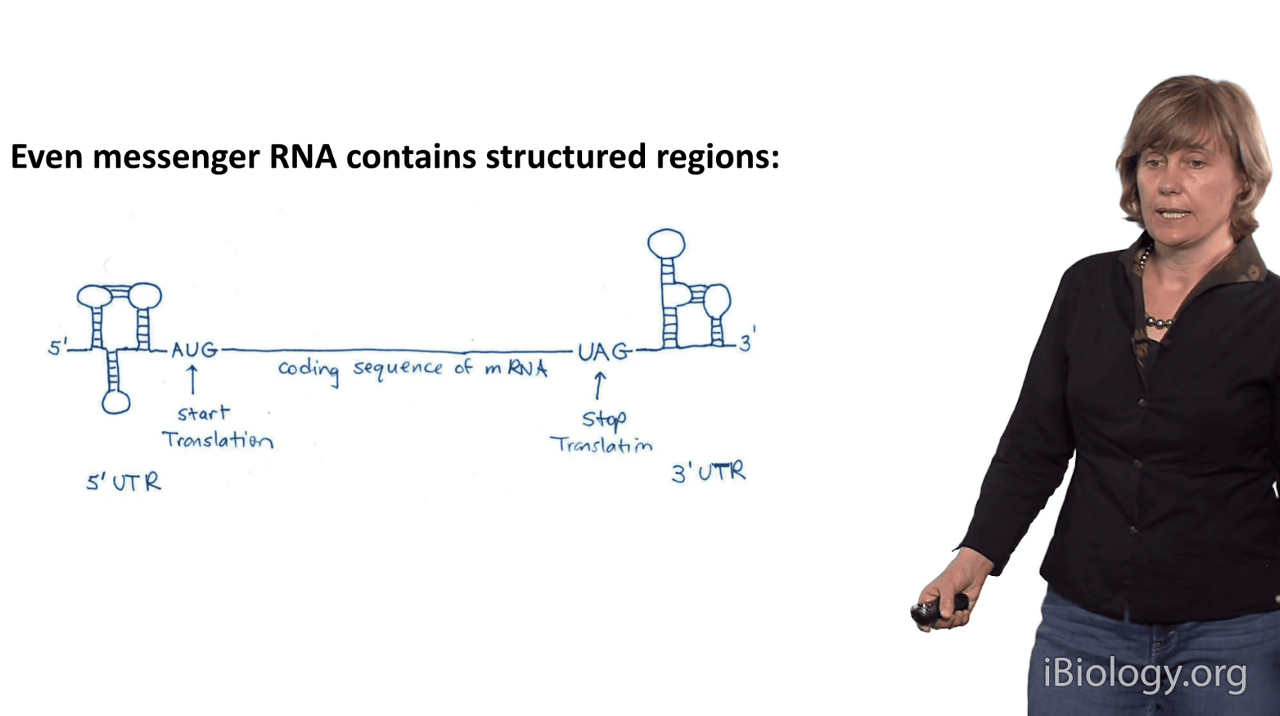
But even if you're most interested in the function of messenger RNAs,
it's important to remember that many messenger RNAs also contain highly structured regions.
So even though the middle part of an mRNA molecule often just contains the coding region,
the triplets that encode the amino acids for your proteins,
often the RNA sequences, at their termini,
form these complex structures in the untranslated regions
and these help to regulate the process of protein synthesis.
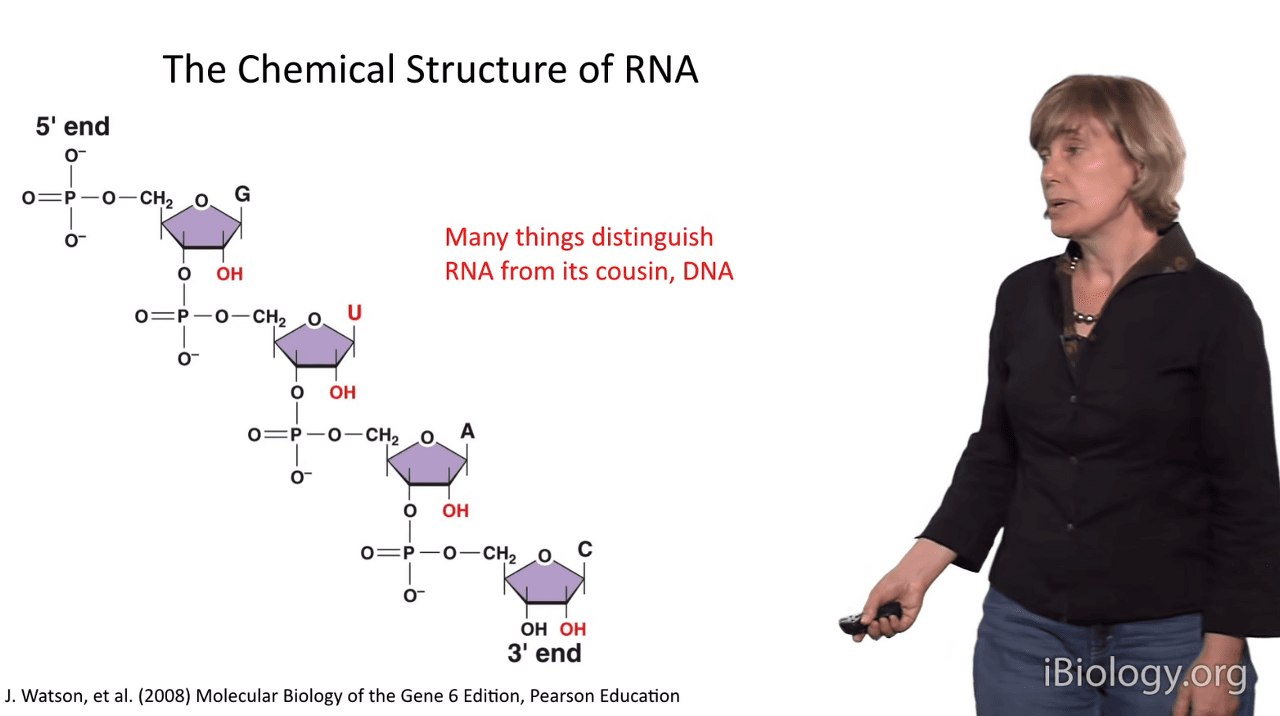
So the chemical structure of RNA is a big part of how it can achieve these many functions
and how it adopt these complex structures.
And a couple of very important things distinguish RNA from its cousin, the DNA molecule.
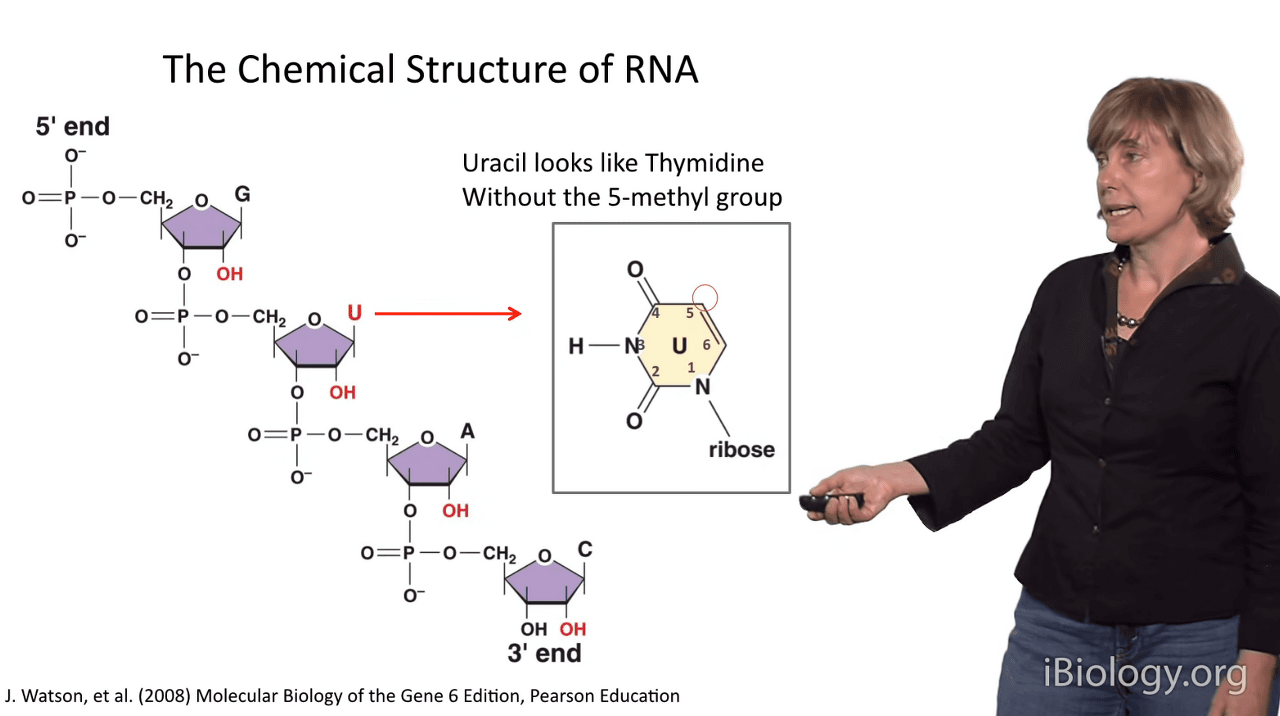
So, in addition to the 2' hydroxyl groups that you see here,
the Uracil base looks a lot like Thymidine,
but it's missing the 5-methyl group at this position.
So, one of the bases on RNA is different than it is on DNA.
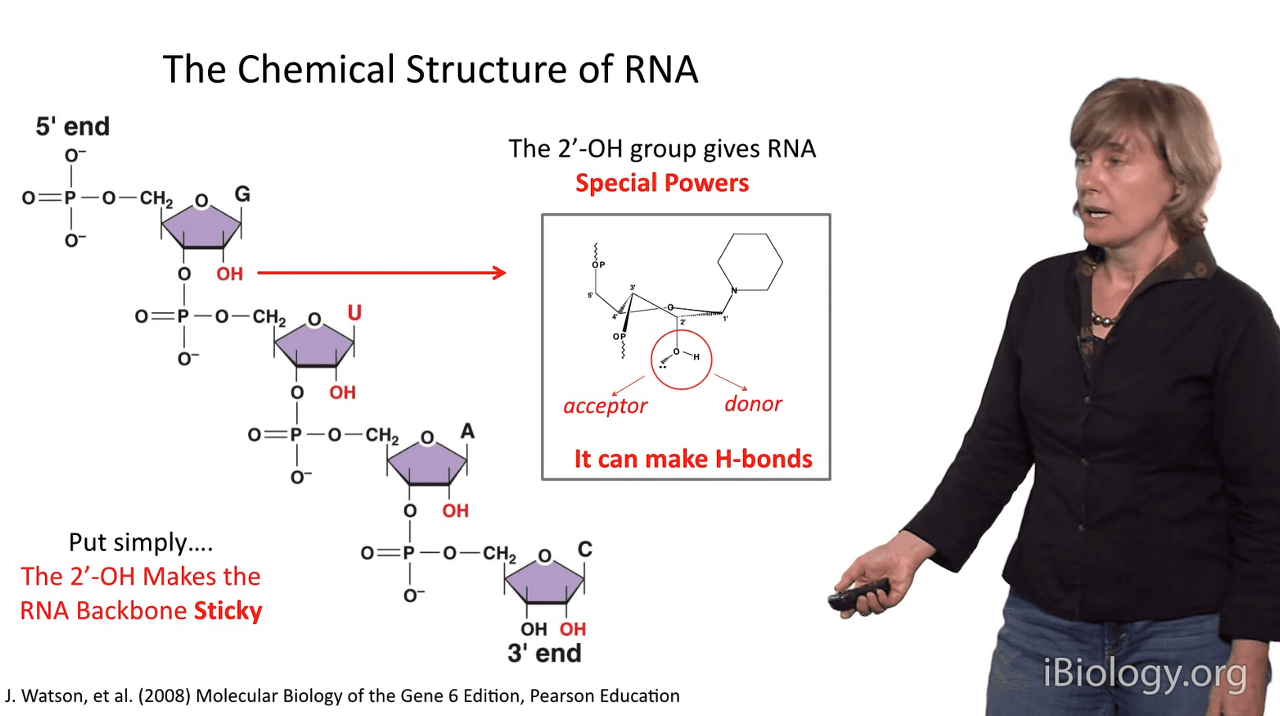
But, back to the 2' hydroxyl group (2'-OH),
which is really the thing that endows RNA with special capabilities.
I like to say the 2'-OH group gives RNAs "Special Powers",
and the reason for that is that this substituent can both accept and donate a hydrogen bond.
So, every 2'-OH group can make up to two hydrogen bonds.
So, the bottom line is that makes the RNA backbone very sticky
and enables RNAs to make a number of types of interactions
that are impossible if you just have a deoxyribose at this position.
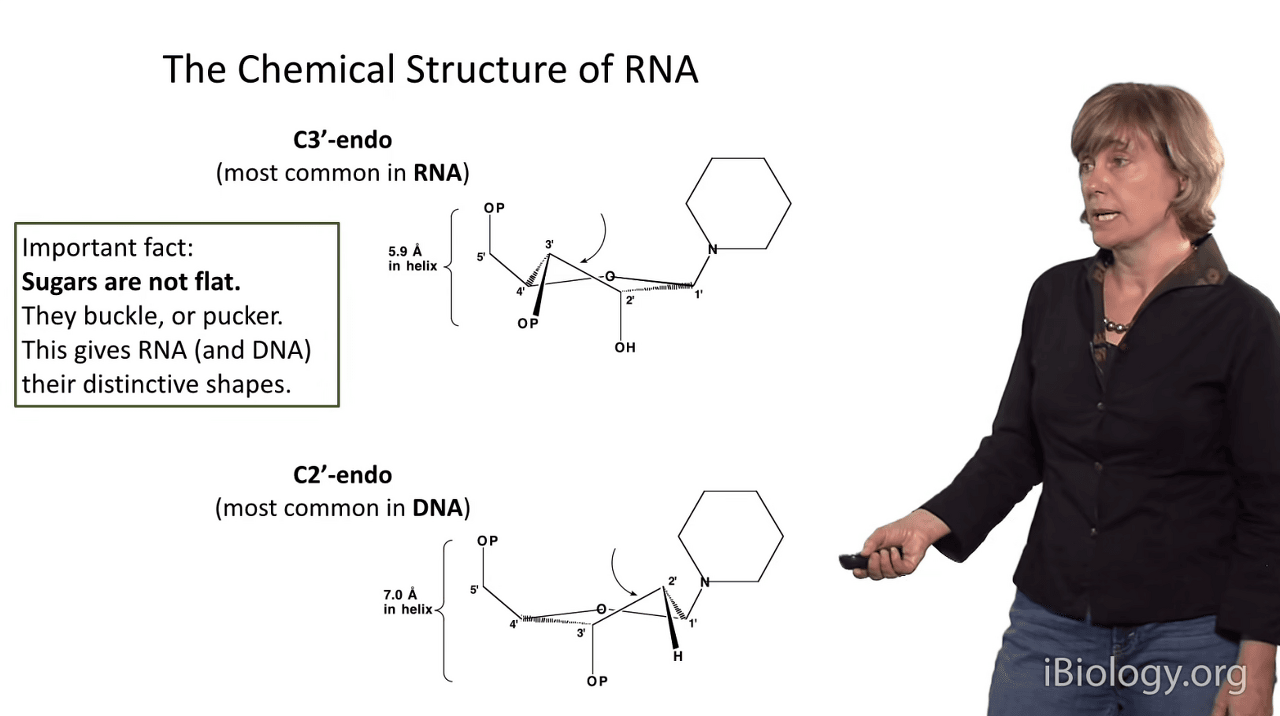
In addition to the chemical structure of RNA,
another thing that gives it its shape and distinguishes it from DNA is the structure of the sugar moiety.
So a lot of times people think that the things that make DNA and RNA molecules special are the sequences of the bases and the base pairings between them.
But a lot is going on with the sugar-phosphate backbone,
and in particular it's important to remember that sugars are not flat.
Because they're five-membered rings,
they often buckle or pucker, and this gives both RNA and DNA their distinctive shapes,
and we'll be talking about those more in a moment.
There are two main conformations of the sugar pucker in a ribose
and one of them is the C3'-endo pucker.
And so if we imagine the sugar is in this position here,
the 3' atom of the sugar pushes up,
I like to say it's pushing in toward the plane of the base,
and this gives you the C3'-endo conformation.
The consequence of that conformation is that the inter-phosphate distance is very small:
it's only 5.9 Angstroms in an RNA-like sugar.
However, these sugars are always flexing,
especially if they're in the absence of surrounding structure,
and an alternative conformation that can be adopted by ribose is the C2'-endo conformation,
which is actually the one that's dominant in DNA.
And that occurs when this carbon kicks it's knee up and,
at the C2' position, becomes closer to the base.
The consequence of that is that the inter-phosphate distance gets very large:
it's 7 Angstroms.
And that's why you'll see, later in the presentation,
that DNA duplexes are more elongated and spread out than RNA duplexes.
It also is an important factor in giving RNA and DNA their helical shape.
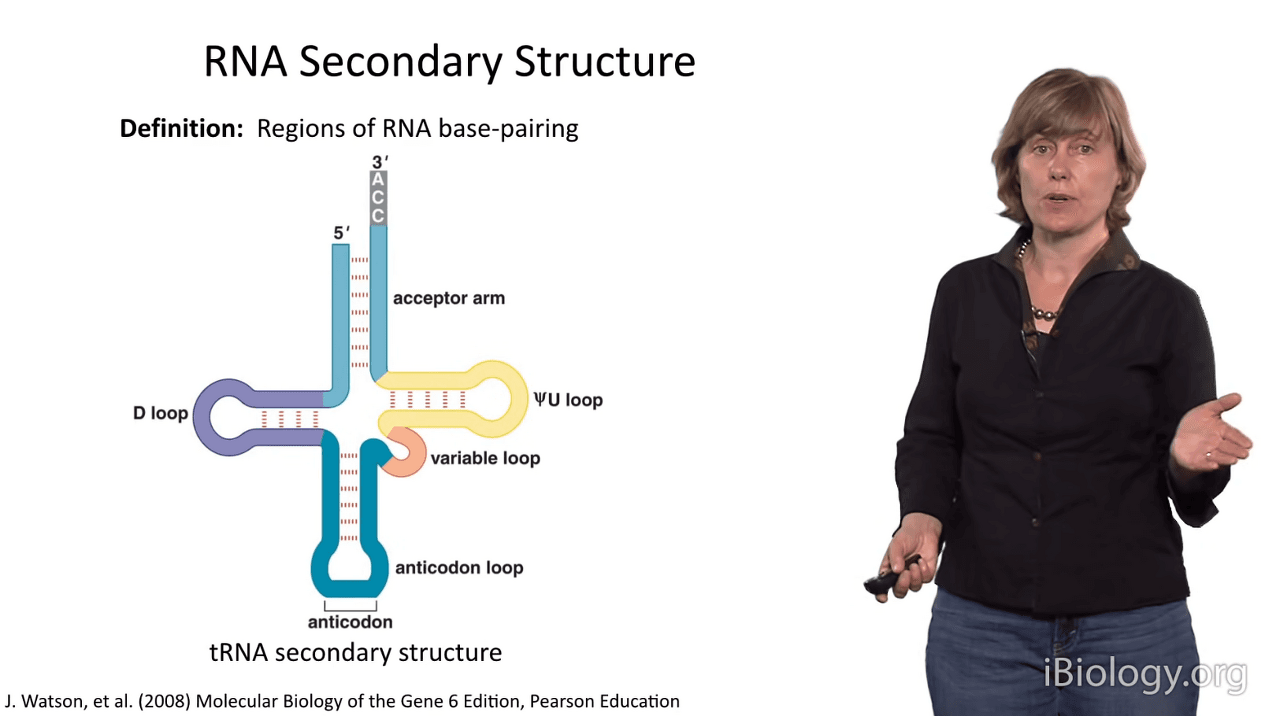
Okay, so now that we've covered some of the most important aspects of primary structure in nucleic acids,
let's talk a little bit about the secondary structure.
And some terminology is helpful.
First of all, it's important to define RNA secondary structure as the regions of RNA base pairing.
So, I'm exemplifying this with the secondary structure of tRNA.
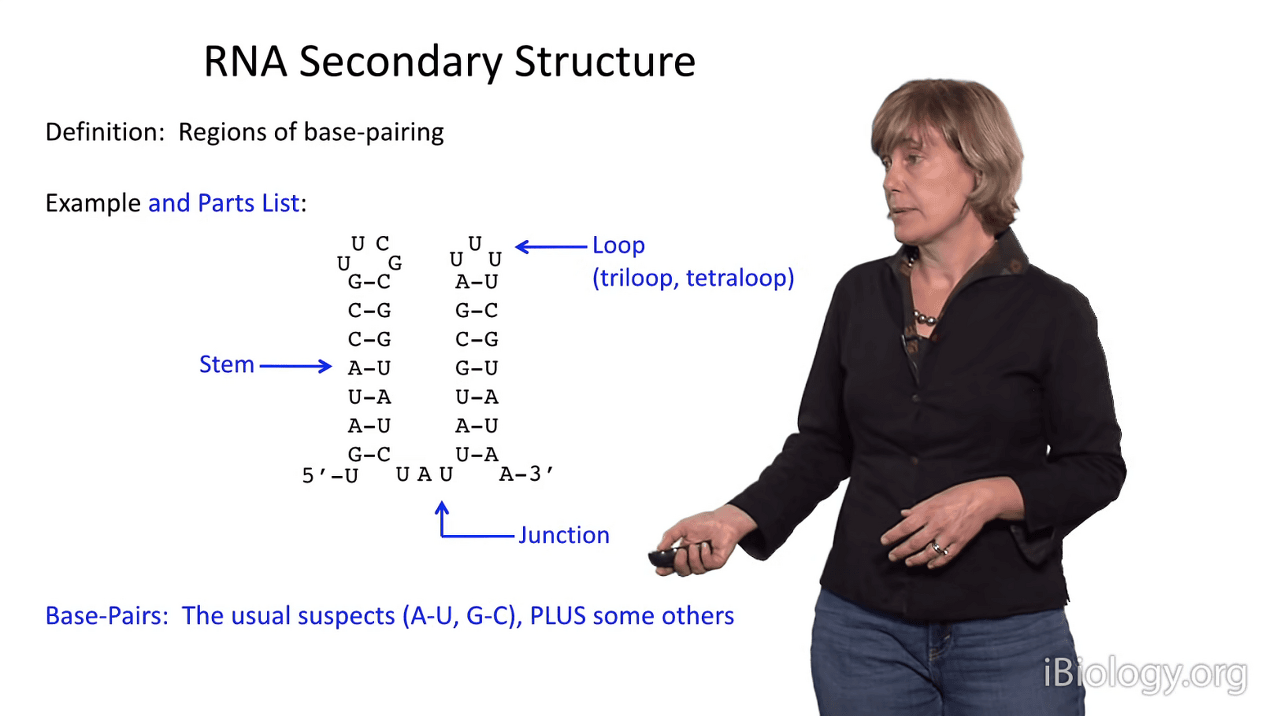
But first, let's look at the parts list a bit.
I'm showing you here, a simplified representation of two stems.
And so, if we were to discuss these, you would see that there are two duplex stems in this structure.
One of them is capped by a hairpin loop,
and often these are triloops, with three nucleotides, or tetraloops, with four nucleotides.
And in this case, and in many cases,
stems are joined by substructures that we call junctions.
The base pairs in an RNA secondary structure are the usual suspects: A-U, G-C,
but in RNA alternative base pairings are readily tolerated.
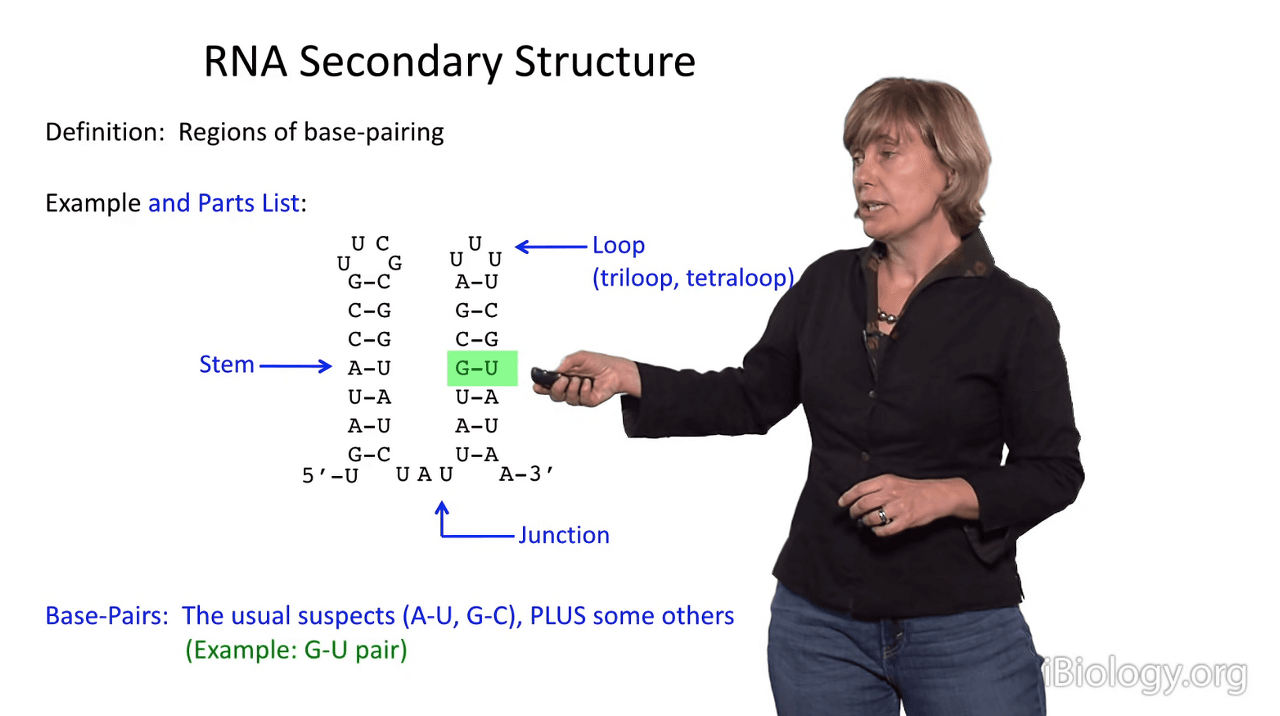
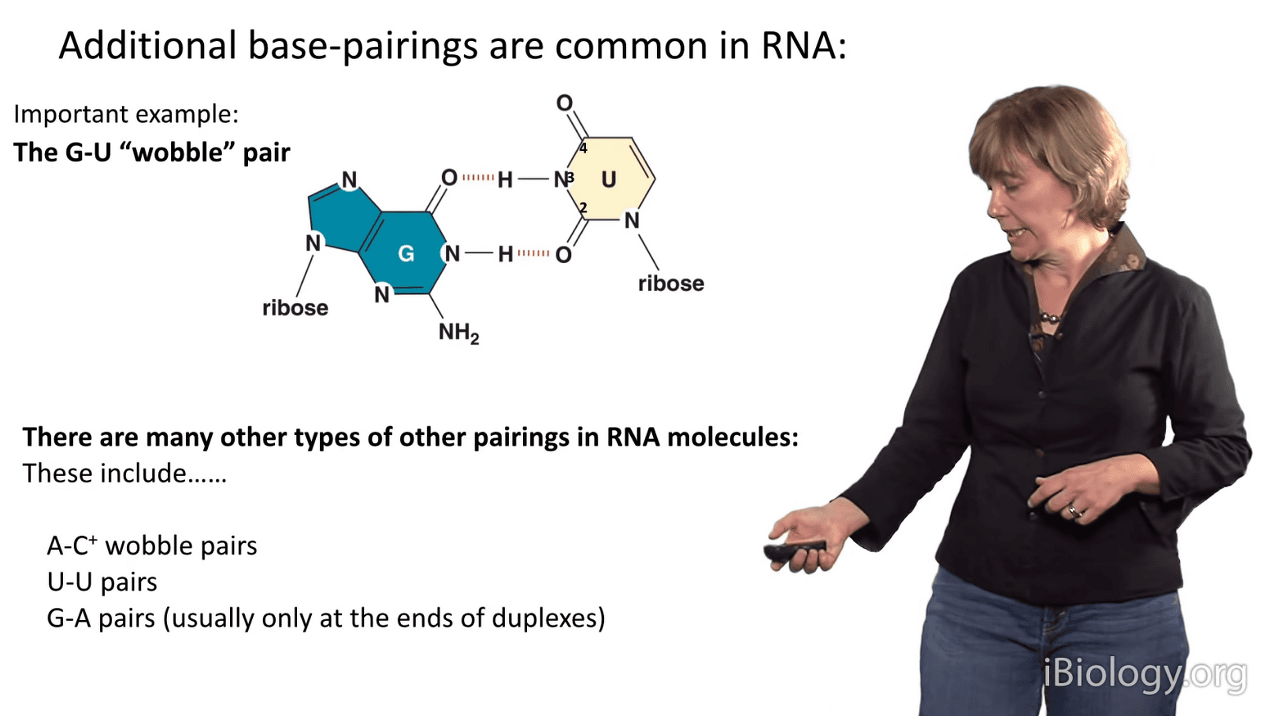
And I'll show you one example, that is the G-U wobble pair.
In G-U pairs, there is a structure that differs slightly from Watson-Crick base pairing.
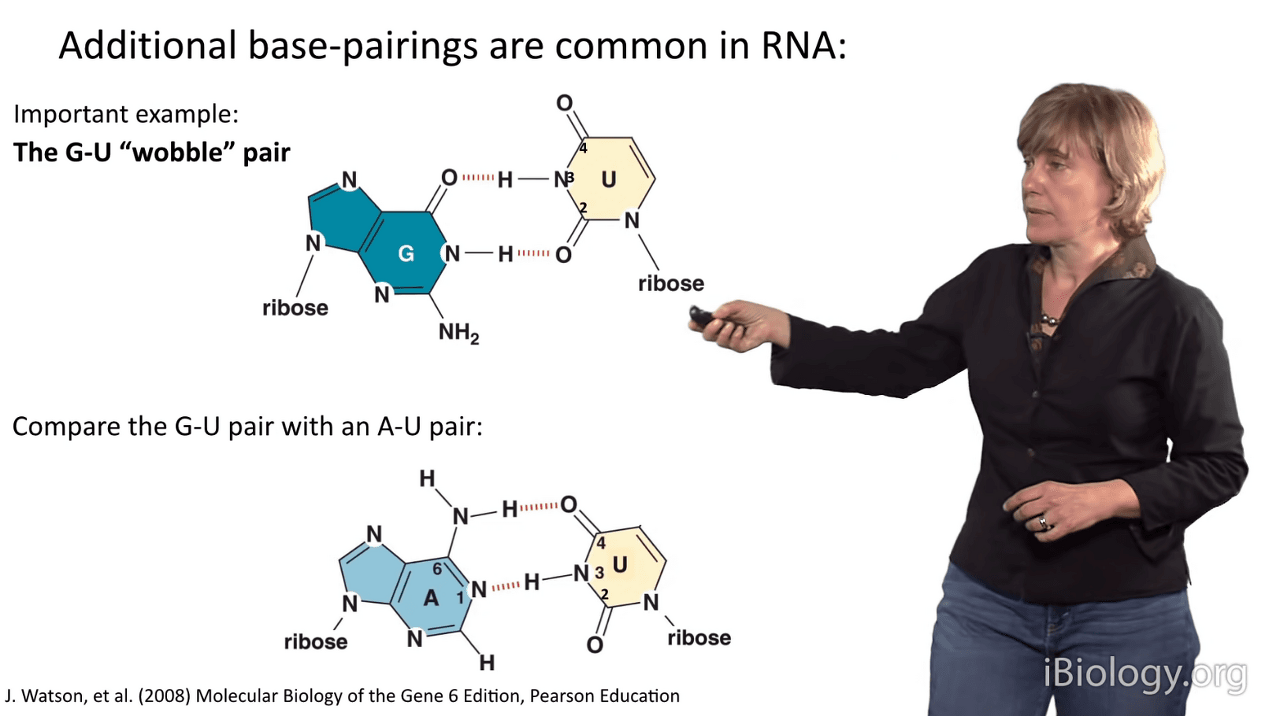
What we see in a G-U wobble pair is that the line of the bases is slightly different
because they have a different hydrogen bonding arrangement than an A-U pair does, which you can see down here.
You can see that in the G-U wobble pair, the uridine is displaced upward in this representation,
and then that also causes this amine group in the guanosine to project far out into the minor groove of RNA.
So, interestingly, when you have a G-U wobble pair in an RNA duplex,
it has almost no perturbation to the structure
that you can see by eye when you solve the structure.
So, it's readily tolerated and has a similar stability to an A-U pair, in RNA anyway.
There are other kinds of weird base pairings that are tolerated.
At certain pHs, cytosines become protonated and we see A-C wobble pairs.
It's often common to see uridine-uridine pairs and G-A pairs,
although because these involve two purines, that are large bases,
they're typically only seen and stabilized at the ends of duplexes.
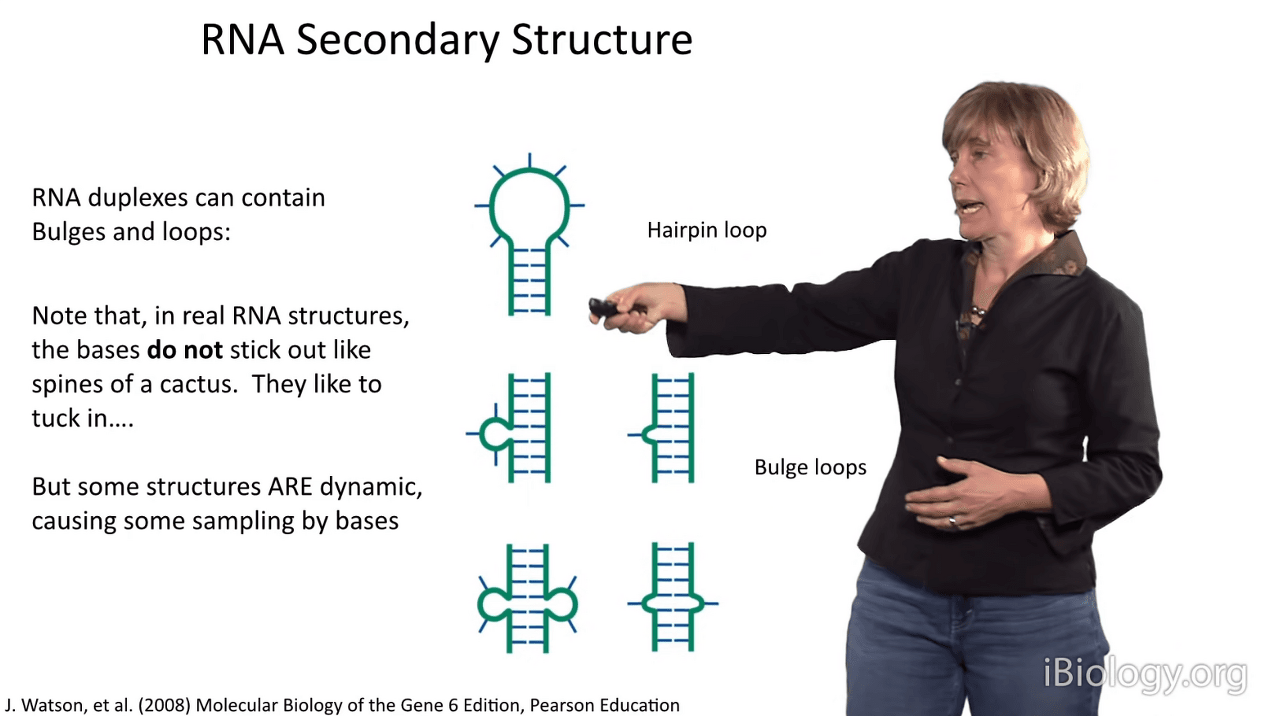
So what are some other kinds of RNA secondary structural arrangements?
I've just shown you that you can have duplexes that are terminated by hairpin loops, that connect the strand,
but there are other types of loop structures that have important significance for the overall structure.
There are asymmetric loops, as I've shown you here.
This one has three bases that stick out, and this one has one.
Often times, this kind of arrangement causes a bend in the duplex.
And this is a symmetric set of mismatches and, often times what you observe in a real structure is
that the RNA is not highly perturbed at these positions and that these bases,
which don't like to be out in water, will tuck in and behave as if they were base pairing.
Another thing that is important to point out about representations like the ones
I've just shown you is that, right now, I've shown you loop nucleotides that are sticking out like the spines of a cactus.
It's important to say that this almost never happens
because nucleoside bases are aromatic, like benzene.
They don't like water and they like to stack upon each other.
And so most of the time, they'll make an effort to tuck in to produce specific structures.
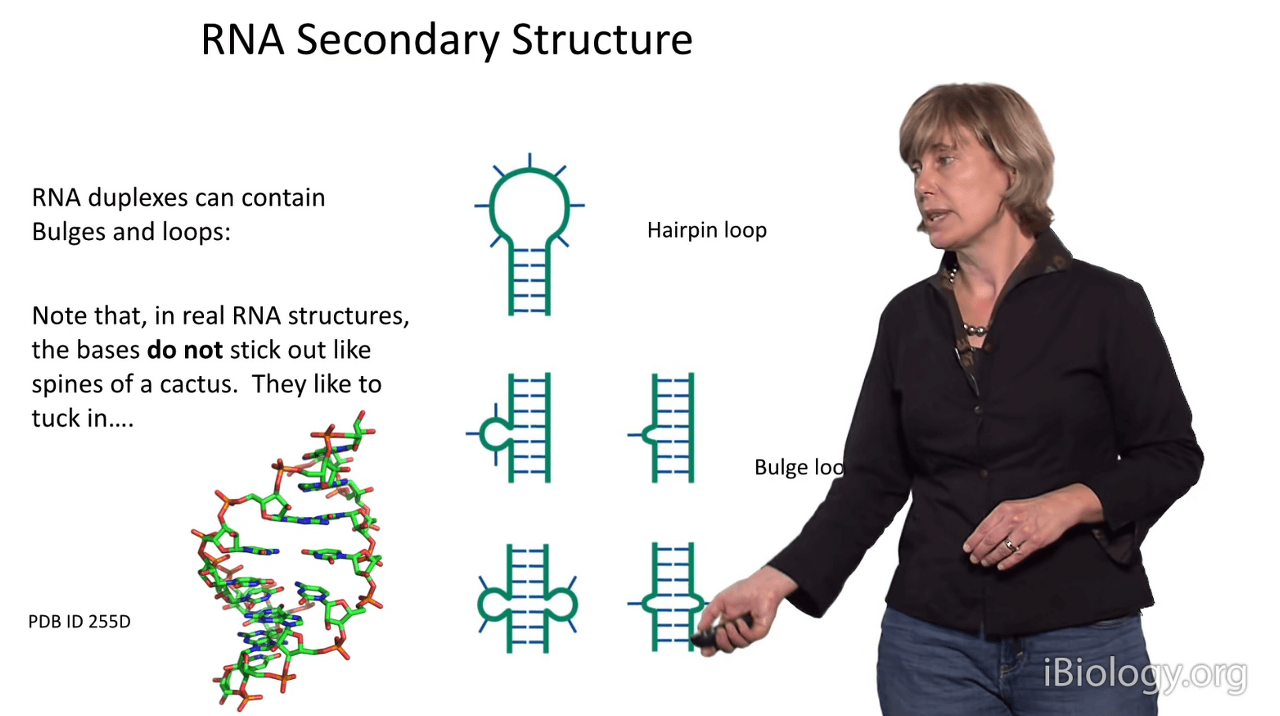
So, when I was saying to you before that mismatched bases,
that are asymmetrical within a duplex, have very little perturbation,
I meant that because that's been seen in high-resolution structures, such as shown here.
You probably wouldn't be able to tell that in this structure,
there are two "unpaired" bases.
They've simply stacked in to get out of the aqueous environment.
Anyway, these are some of the perturbations of RNA secondary structure.
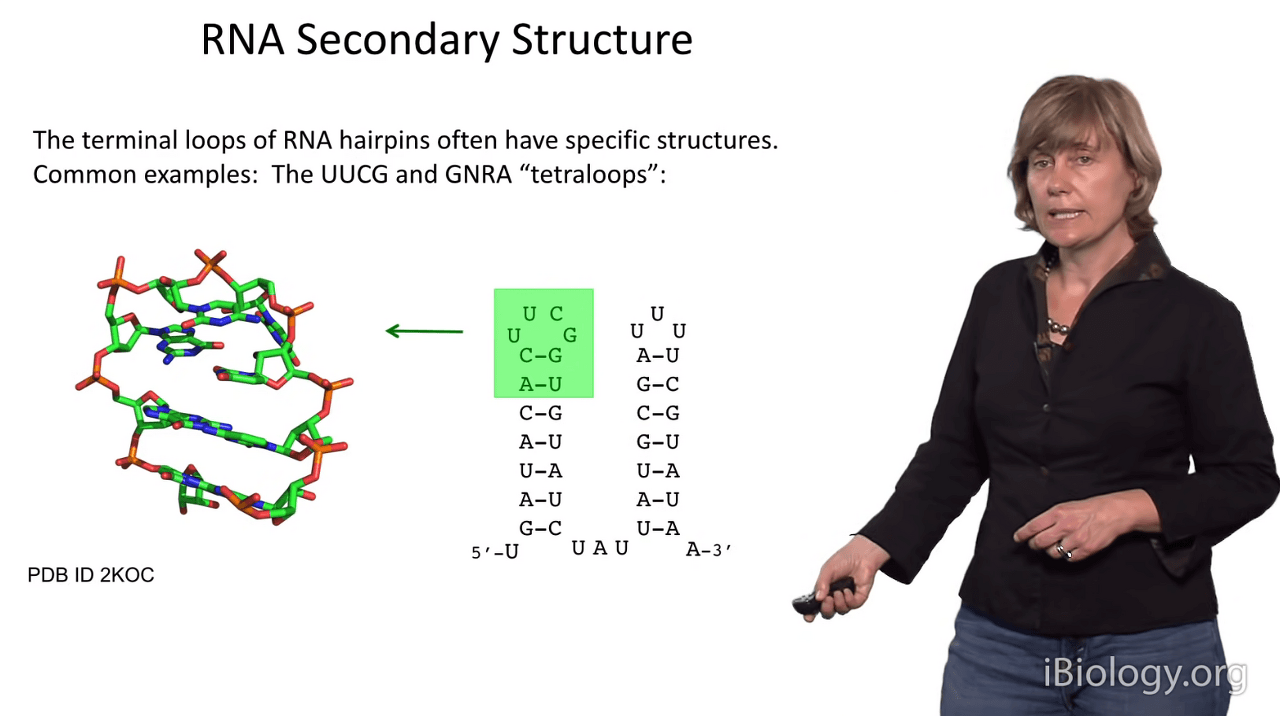
So, one of the things I'd like to point out is that the sequences at duplex termini are often highly conserved in sequence.
This sequence here (UUCG) is frequently found within substructures that require extra stabilization
and, interestingly, if you solve the structure of hairpin sequences like this,
this region here will always have the same three-dimensional structure as shown here,
which was one of the original NMR structures that characterized the arrangement of bases in this sequence.
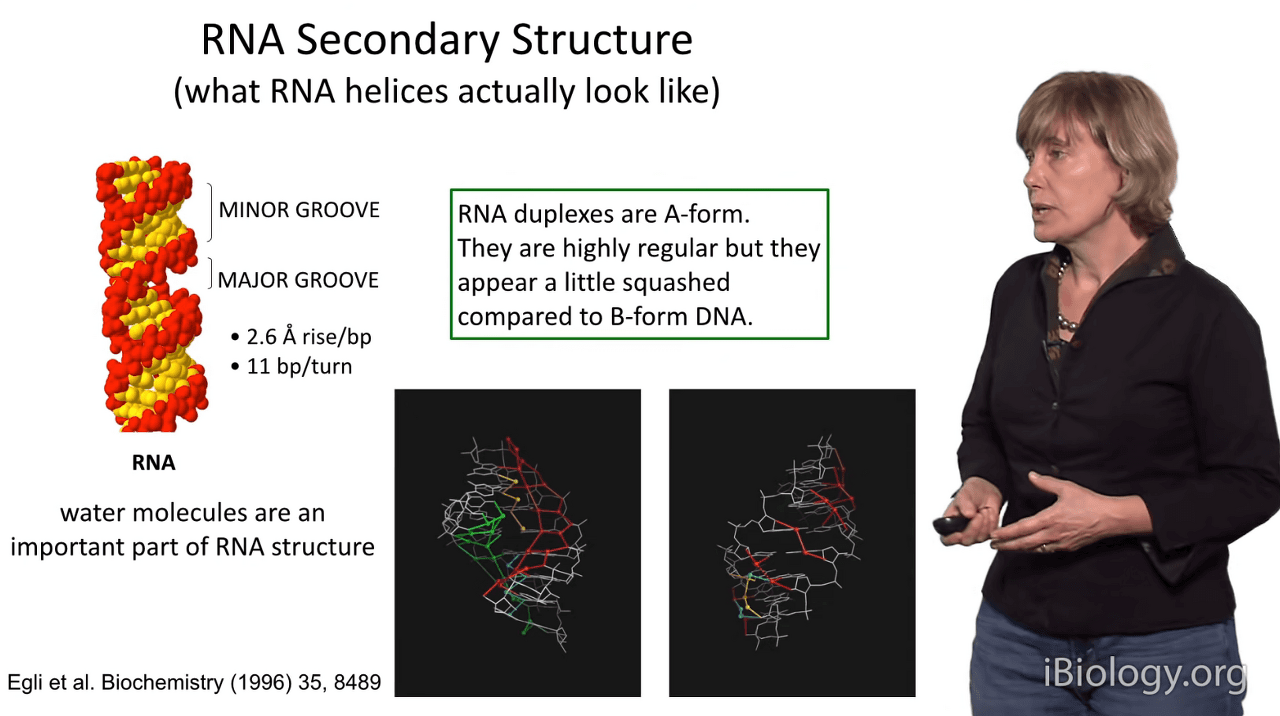
So let's take a close look at the overall topology of RNA secondary structure.
What do RNA helices actually look like?
So we often say that RNA duplexes are "A-form" and that DNA duplexes are "B-form",
but it's important to point out that RNA duplexes have special characteristics.
They tend to be highly regular, but relative to B-form DNA
as we'll see in a minute, they often appear a little bit squashed and compact,
almost as if they were little barrels.
So some features of RNA secondary structures,
if you look at them at high resolution, are that the minor groove actually looks like the bigger groove in RNA,
and its very large and very flat.
The major groove is very narrow and quite deep.
One of the reasons that RNA duplexes look more squished together is that there's only 2.6 Angstroms between each set of stacked bases.
I also like to point out that RNA and DNA molecules don't just include the atoms inherent to the RNA and DNA:
water plays a very, very important part in their structure
and when we obtain ultra high-resolution crystal structures of RNA and DNA,
you see that water is an integral part of the structure
and often forms beautiful lattices that connect the polar regions of the molecule.
So for a minute now, let's compare RNA with B-form DNA.
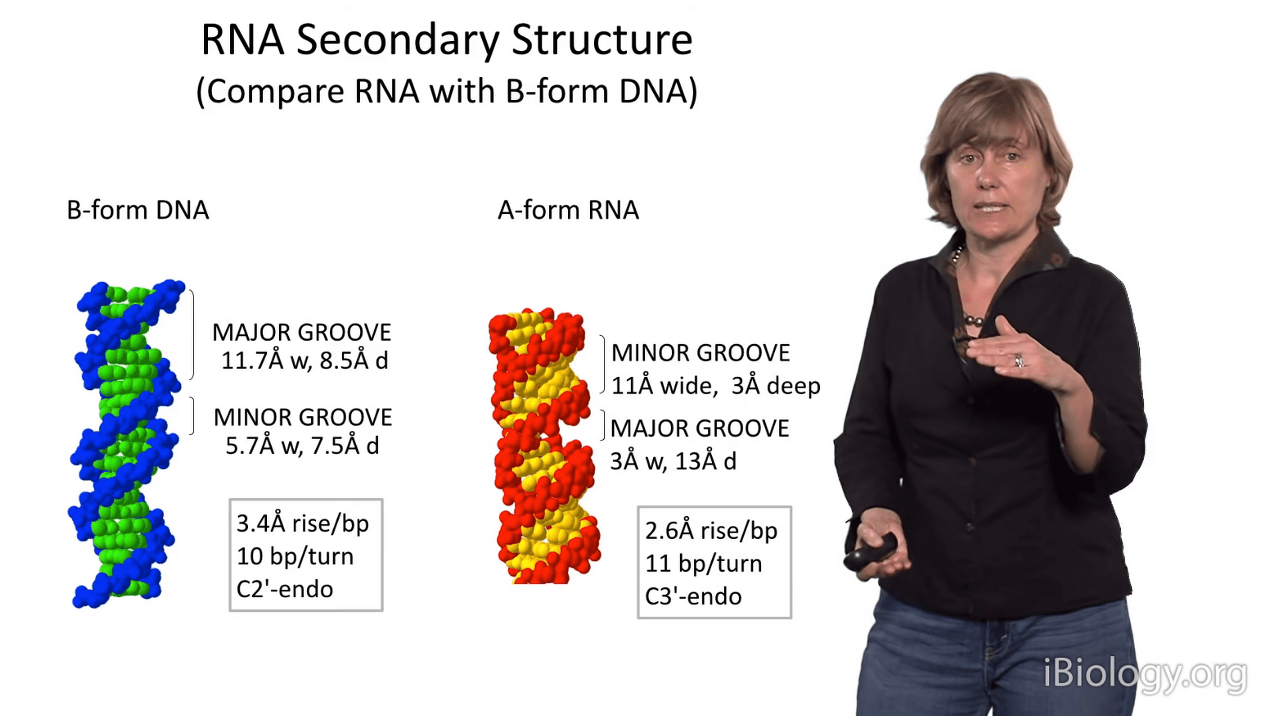
As I mentioned before, B-form DNA appears more elongated
and that's because it has 3.4 Angstroms between each set of stacked base pairs.
In B-form DNA the major groove is really wide and it's somewhat deep.
The minor groove is less wide and it has about the same depth as the major groove.
And, interestingly, in DNA there are 10 base pairs per turns.
And, remember the sugars have that conformation
that gives them that long inter-phosphate distance,
thereby giving rise to a longer polymer.
RNA is quite different:
you can see that it has 11 base pairs per turn, because there is less space between the base pairs
and as I mentioned before, the major groove is very deep,
but the inter-phosphate distance across the groove is really short.
And the minor groove is quite wide and shallow.

So now we've talked about what RNA duplexes look like and what they're made of,
but an important thing to be keeping in mind is how stable they are
and how you can determine their relative level of stability.
Now, one can do this simply by knowing their sequence,
and this is a result of the work by an investigator named Doug Turner,
who figured out that RNA duplexes are not simply stabilized by the number of base pairs, or hydrogen bonds between the base pairs.
The relative stability in an RNA molecule and in an RNA duplex is dictated by the stacking between neighboring base pairs.
And he came up with a set of rules, called Turner's Rules,
that tell us that for a given set of neighbors, depending on the nearest neighbors,
you'll have a very set free energy of stabilization for that given sequence.
So for example,
here you can see that for a U-A base pair that's stacked upon an A-U base pair,
you have 1.1 kcal/mol of thermodynamic stabilization.
But, intriguingly, if you have a G-C pair that's stacked upon a C-G,
it's 3.4 kcal/mol of stabilization.
And so, if you know the sequence of your duplex, as I've shown here,
what you can do is you can actually sum up the nearest neighbor interactions
for each type of pairing and you can determine, just on the back of the envelope,
the stability of a duplex of interest.
You do have to pay a penalty for bringing two strands together to make one,
and that is something that you have to take out of the sum,
but the bottom line is that all the different computer programs that you use to calculate stabilization of an RNA,
or in the case of DNA to calculate the stability of a primer, are based on this nearest neighbor concept.
So we've just discussed the elements of RNA secondary structure
and we've also talked about what kinds of features stabilize RNA secondary structure,
so now we're going to put all of those pieces together
and describe the elements of RNA tertiary structure
and discuss a little bit how it forms as well.
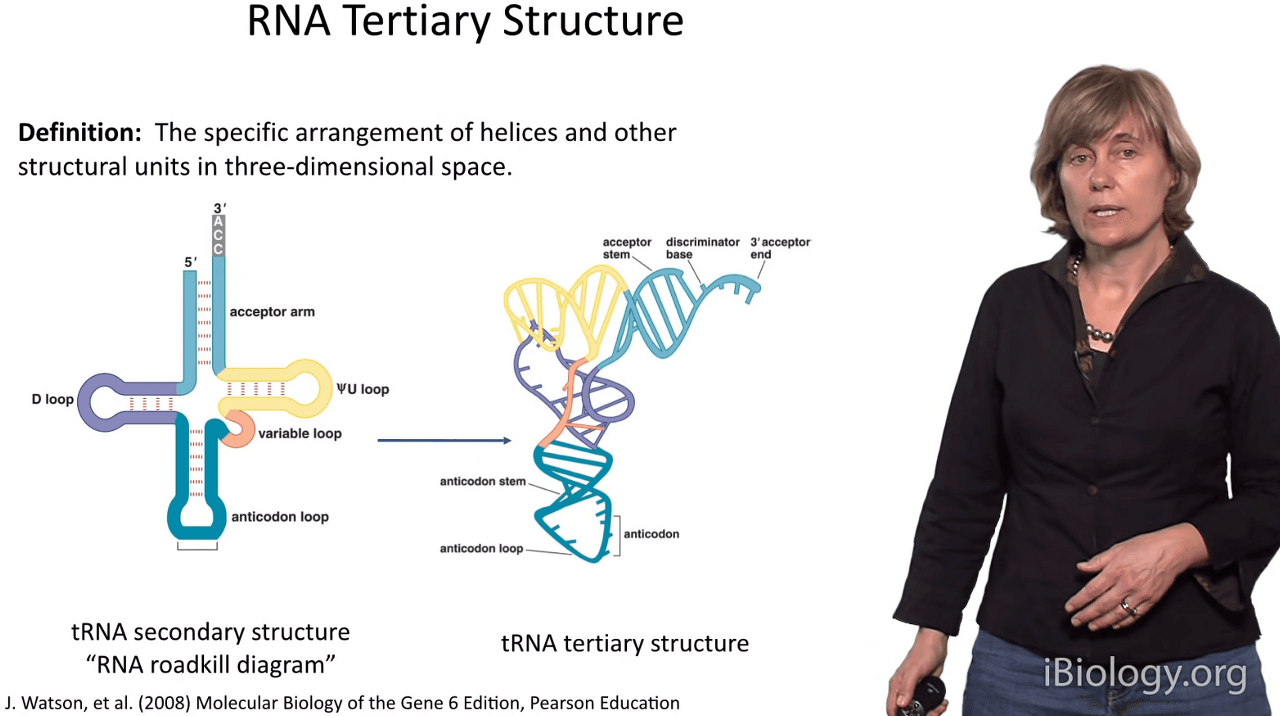
So I define RNA tertiary structure as the arrangement
of helices and other structural units in three-dimensional space.
The way I like to think about it is:
it's going from here, secondary structure,
to here, the globular structure and functional structure of an RNA.
And the example I'm showing you here is a tRNA.
Very often we call the secondary structure the "RNA roadkill diagram"
because it looks like the RNA has been run over by a truck.
And, in the presence of magnesium,
which is the most important feature in stabilizing three-dimensional RNA structure,
we get these beautiful shapes.
And so I'll try to walk you through this process.
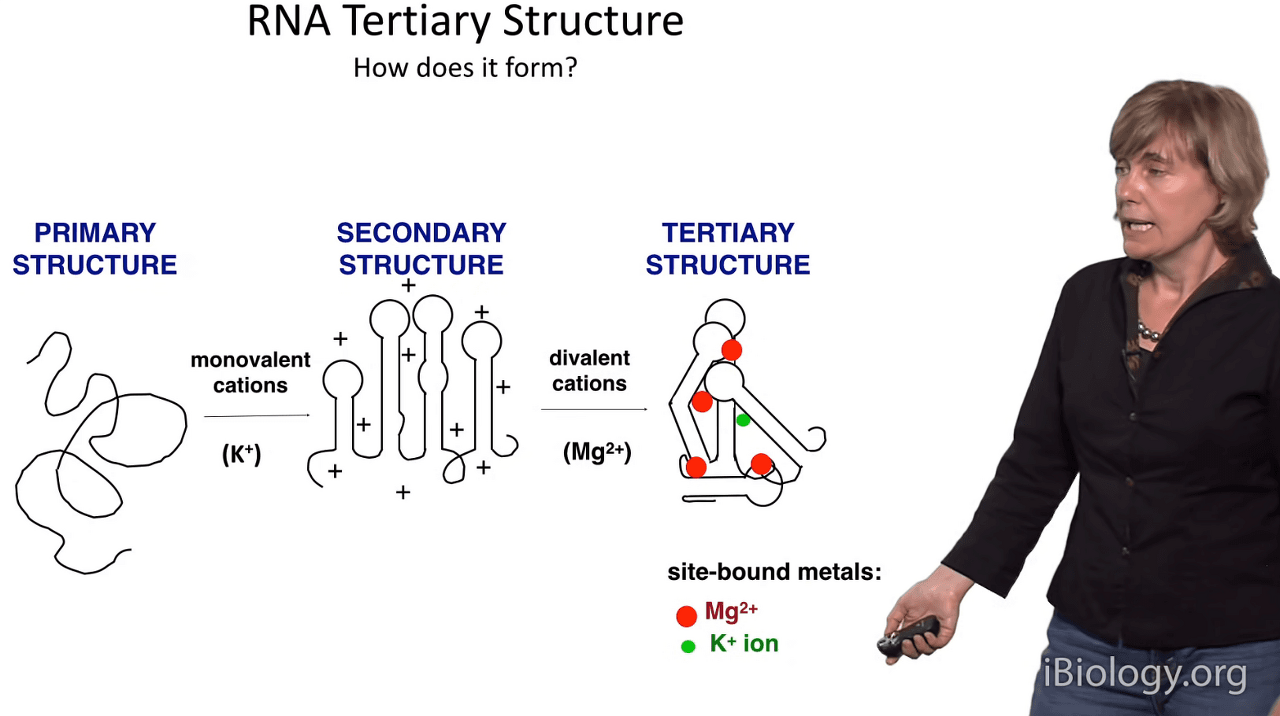
So how does RNA tertiary structure form?
Well, we've discussed the primary sequence of RNA
and I'm showing it to you here as if it were a very disordered spaghetti-like structure,
but if you were to add monovalent cations of any type, and especially monovalent cations,
you would be able to achieve the secondary structure of your RNA.
And in the secondary structure, as we've discussed,
you have your regions of double-stranded and loop character.
Now when you add divalent cations,
and in our cells those are usually magnesium ions,
then we can move from here to here,
and attain the arrangement in three-dimensional space of these elements
and we can observe tertiary structure formation.
It's worth pointing out at this point that in our cells,
the primary cations that are going to be available for RNA structure formation
are going to be potassium, as the monovalent ion, and magnesium.
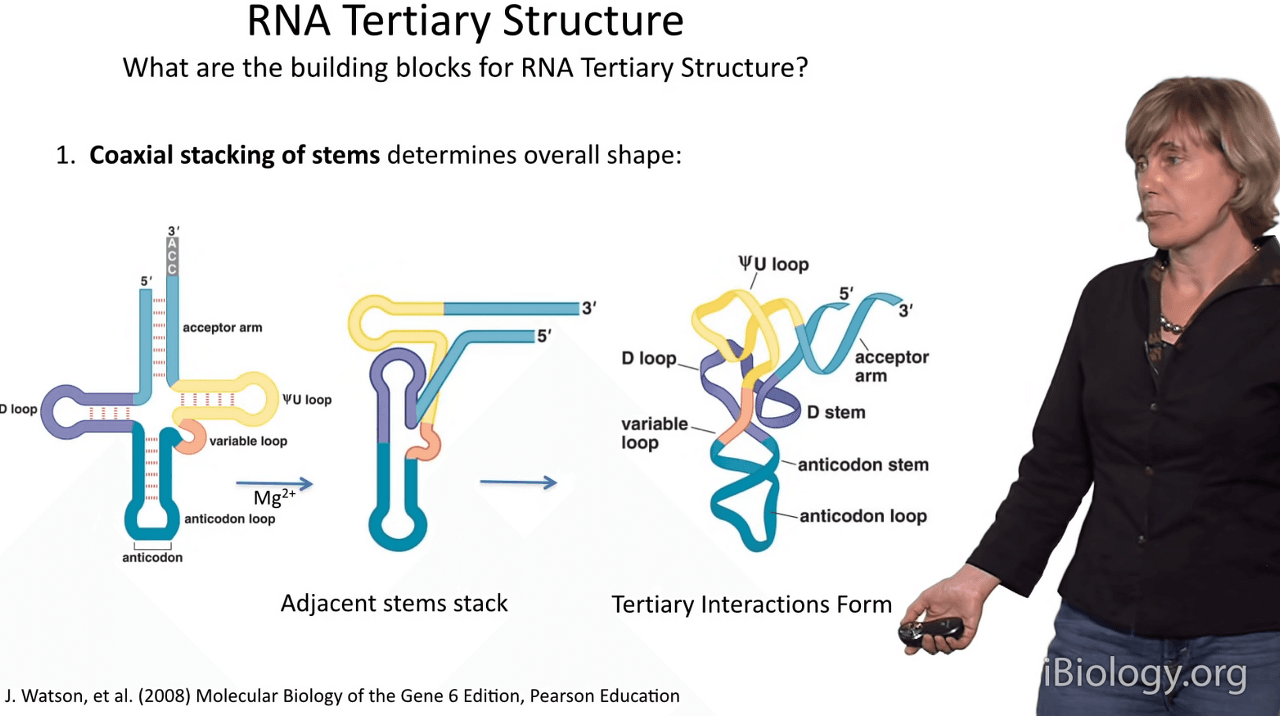
So what are the building blocks for RNA structure during its formation?
Well, again, let's imagine we start out with the secondary structure, our roadkill diagram.
The first thing that's going to happen
when that molecule encounters divalent cations like magnesium is a process called coaxial stacking,
in which regions of short duplex, shown here,
actually stack on one another to form long contiguous duplexes.
In this part B here, you can see that the yellow stem stacks on the light blue stem
and the purple stem stacks on this cyan stem to form two long duplexes.
And this is usually the very first phase of the process.
At that point, then tertiary interactions form and we'll be discussing the details of some of those,
and this gives rise at the end to the globular structure.
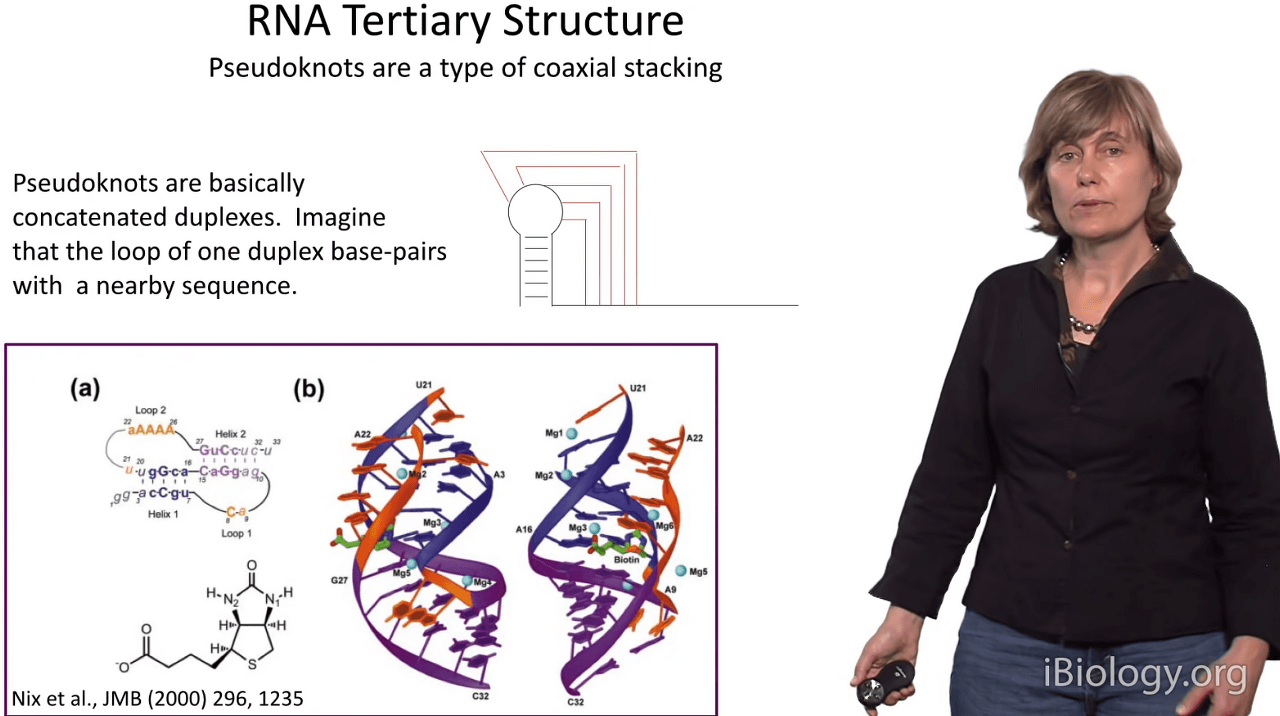
So, because the building blocks of RNA tertiary structure are often RNA duplexes,
I'd like to review a few tertiary structures that are primarily composed of base pairing.
One of the most interesting and prominent in all structures is the pseudoknot structure.
And a pseudoknot is an interesting motif in which you have basically an RNA hairpin loop,
and the loop nucleotides form Watson-Crick base pairs with an adjacent strand.
And when this happens, amazingly, these two duplexes stack on top of each other
as in this structure of a receptor for biotin and
they form one contiguous duplex and the intervening strands snake through the major and minor grooves.
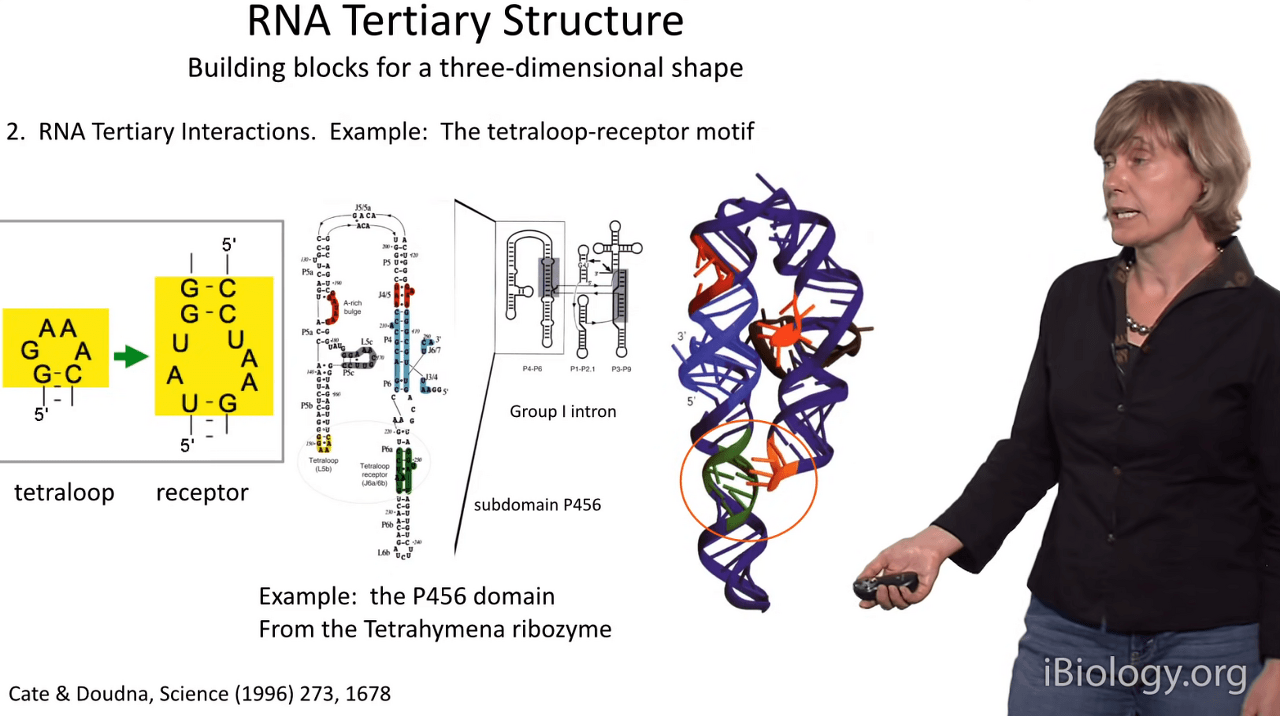
Another building block for three-dimensional shapes in RNA is called the tetraloop-receptor motif
and it was first visualized by Cate & Doudna
when they elucidated the substructure of a folding motif in a group I(1) intron.
And in this structure, another highly conserved tetraloop,
which I'm showing you here,
docks with a very conserved internal loop that's known as its receptor.
It's worth noting that very commonly in conserved RNA molecules,
many of the tetraloops will have this sequence 'GAAA'
and that's because that sequence is likely to have a partner
somewhere else in the molecule of this same sequence.
And when they come together, as shown in this crystal structure,
they dock together and they stabilize and bring together distal portions of the molecule.
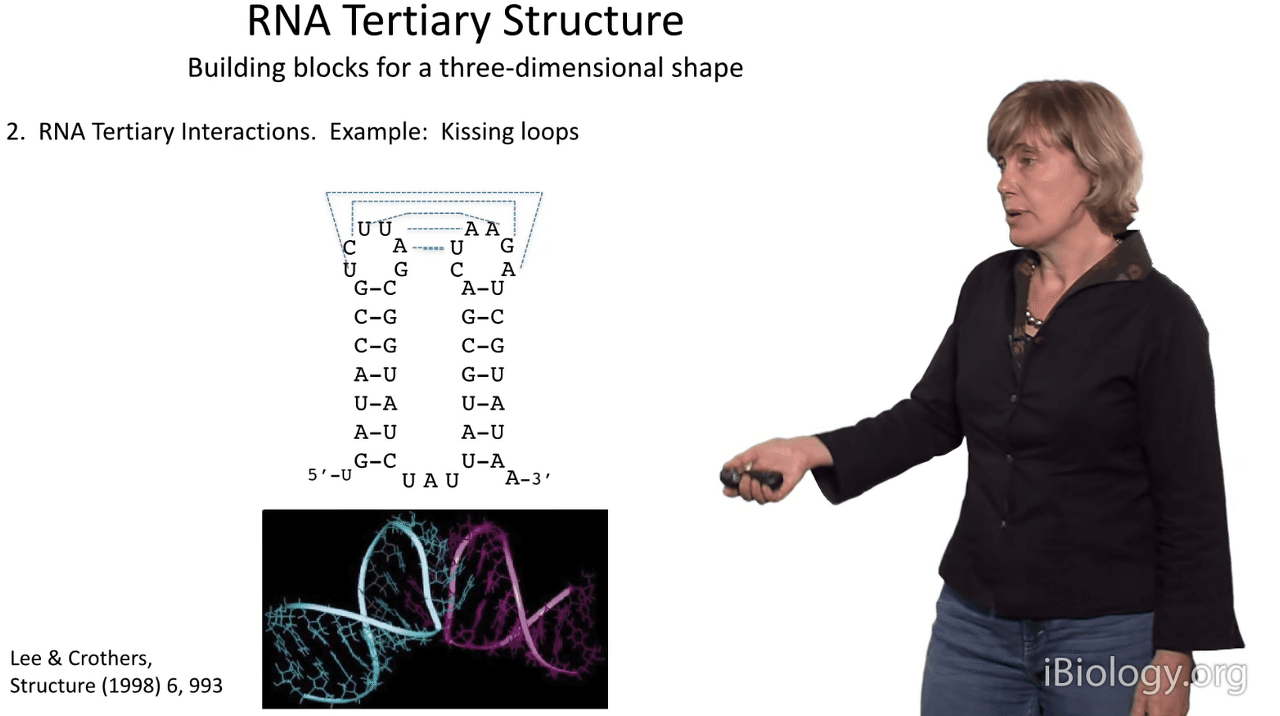
Another substructure that's based on Watson-Crick pairing is the RNA kissing loop,
whereby if you have adjacent stems,
often times the loop sequences can actually form Watson-Crick base pairs with each other.
And it's amazing that this can form and that the intervening backbones permit this arrangement of the two duplexes.
And this was first visualized by Lee & Crothers, who saw that here is the loop duplex forming
and coming out of either side is the stem duplex, giving rise to an RNA shape that has about a 90 degree angle.
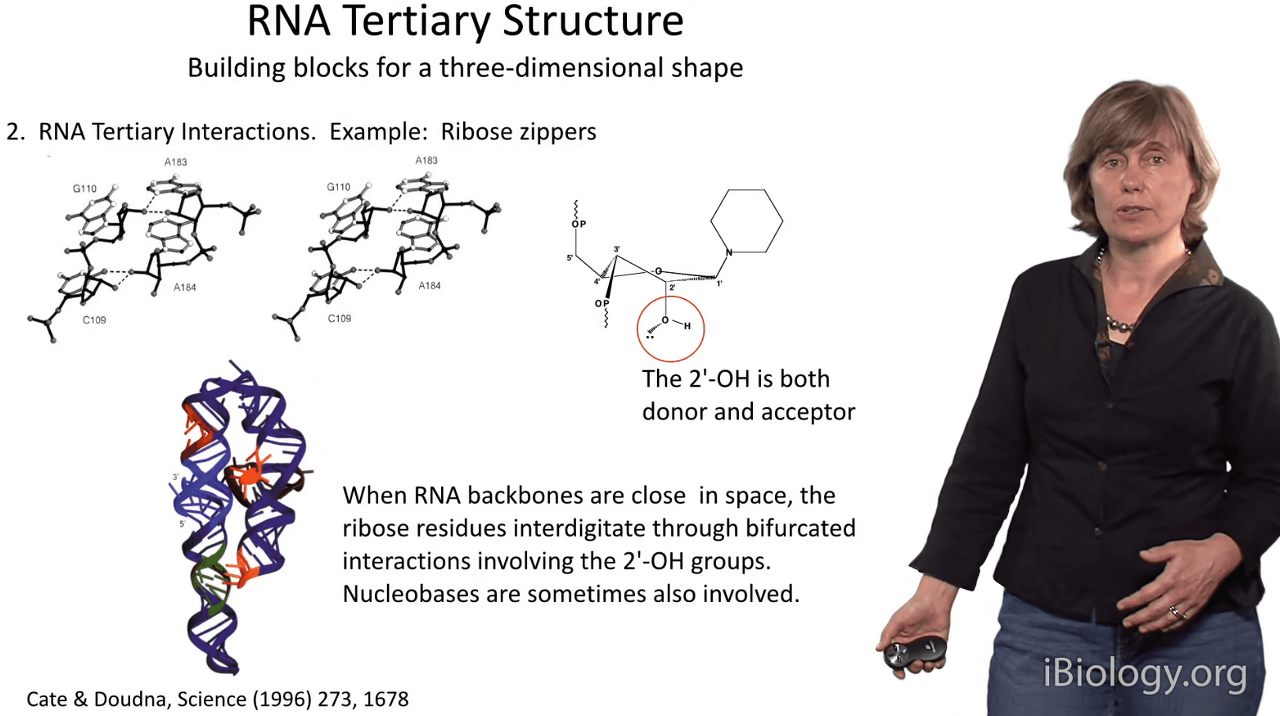
I'd also like to point out that many of the tertiary interactions
that stabilize RNA tertiary structure do not involve base pairing,
but involve the sugar residue,
because remember, the sugar is what makes RNA very, very special.
And again, this is largely due to the fact that the 2'-OH group
is both a hydrogen bond donor and acceptor.
And so one of the most interesting motifs that involves the 2'-OH group is called the ribose zipper.
This is a motif whereby
when sugar moieties on two RNA strands get very close together in space,
the 2'-OH groups actually interdigitate with one another
and form long networks of hydrogen bonds as shown here.
And these kinds of ribose zippers provide extra thermodynamic stabilization
for many RNA substructures that we observe.
You can think of them almost as a glue that helps to knit complex architectural forms together in RNA molecules.
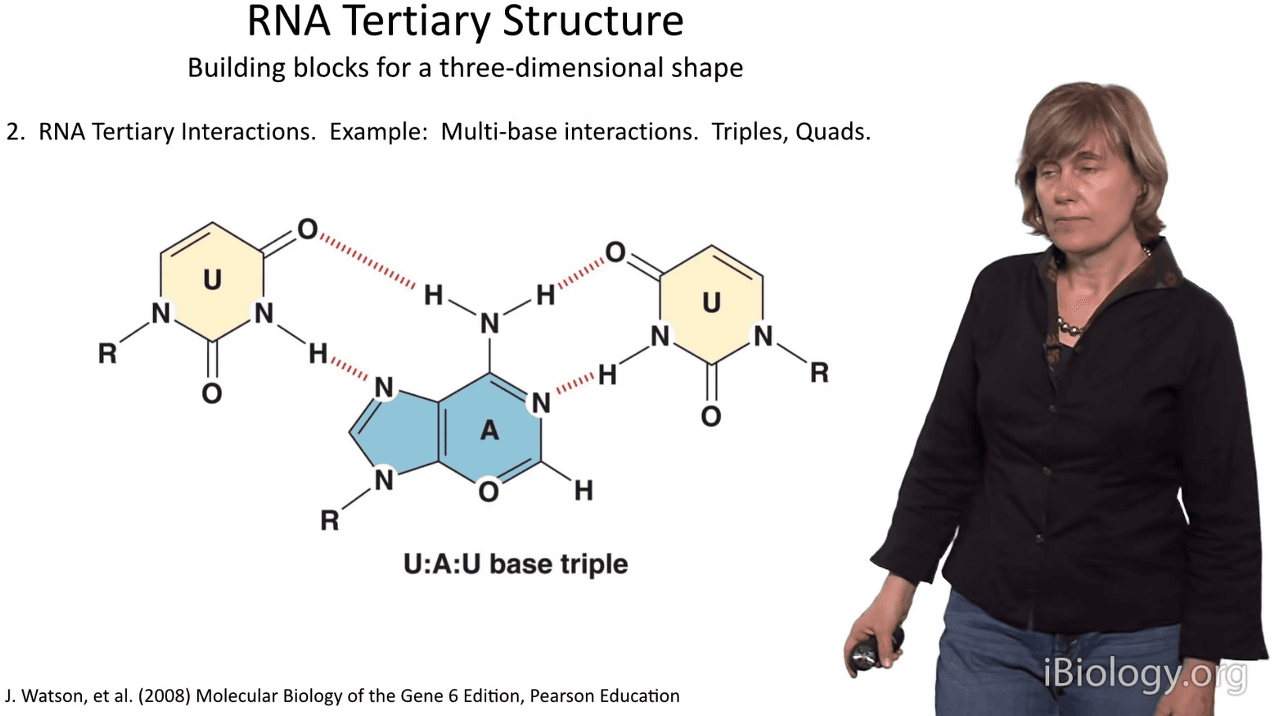
Now, in RNA, we don't just have simple Watson-Crick base pairs between two nucleobases:
RNA molecules often contain three-stranded, and often four-stranded structures
whereby the nucleobases themselves form additional interactions.
This is exemplified here by the fact that an A-U base pair,
shown here, can form an interaction with a third strand nucleotide, in this case a U,
and you can see that there is good complementarity in hydrogen bonding
between the incoming third strand base and the major groove edge of this adenosine.
And we sometimes see these in long arrays, both in the major groove
and in some cases in the minor groove of RNA and these play a very important role in structure.
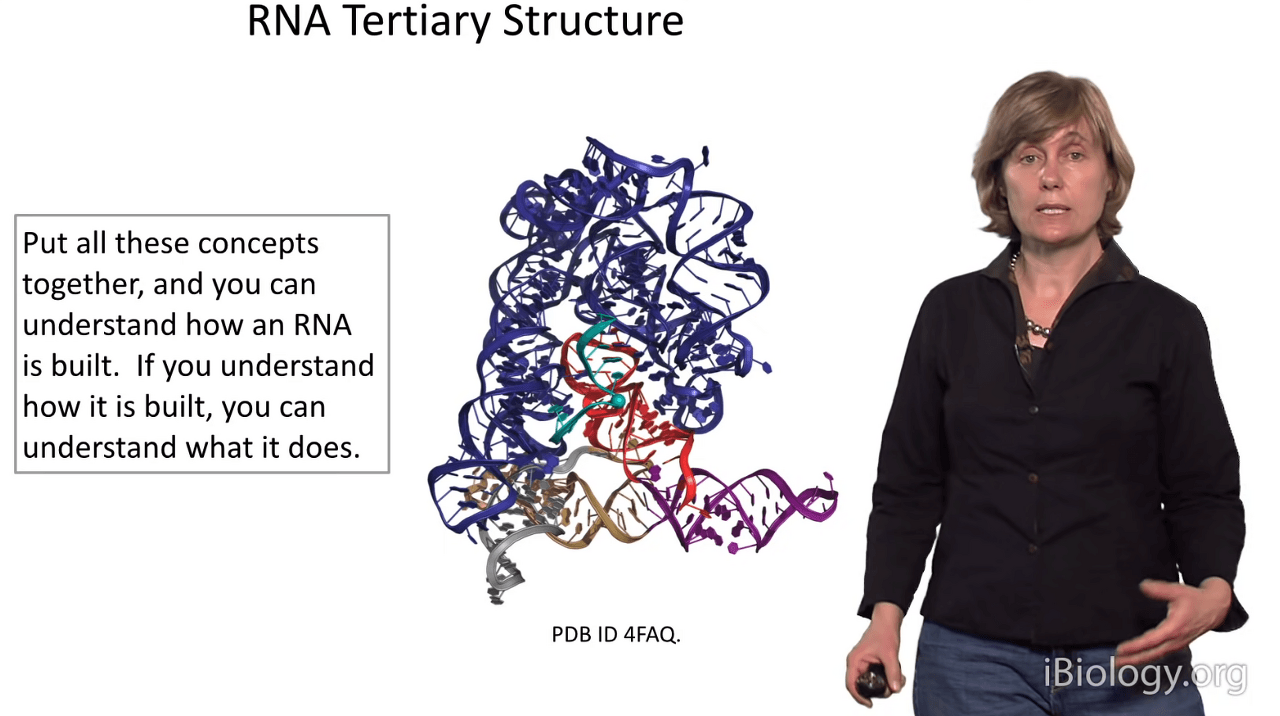
Today, we've talked about RNA primary structure, RNA secondary structure,
and we've talked about the nuts and bolts that put together an RNA tertiary structure,
which can get as elaborate as something like so.
So hopefully I've helped you understand that if you understand how an RNA is built,
you may be able to understand a little bit about its function.
Another thing I hope you came away from this talk with is an understanding
that RNA structures are not just the simple helix that one is used to think about,
but that they can adopt very complicated forms
and this is why we have so much functional diversity in the RNA world.
Thanks for listening!
'과학자로 비롯하기' 카테고리의 다른 글
| Oligonucleotides (0) | 2021.12.26 |
|---|